
Spark的RDD检查点实现分析
。Spark的RDD执行完成之后会保存检查点,便于当整个作业运行失败重新运行时候,从检查点恢复之前已经运行成功的RDD结果,这样就会大大减少重新计算的成本,提高任务恢复效率和执行效率,节省Spark各个计算节点的资源。...
。Spark的RDD执行完成之后会保存检查点,便于当整个作业运行失败重新运行时候,从检查点恢复之前已经运行成功的RDD结果,这样就会大大减少重新计算的成本,提高任务恢复效率和执行效率,节省Spark各个计算节点的资源。...

如果你是从事IT工作1~3年的新人或者希望开始学习Spark核心知识的人来说,本书非常适合你。如果你已经对Spark有所了解或者已经使用它,还想进一步提高自己,那么本书更适合你。...

官方版本的spark1.0.0-hadoop2(hadoop2,cdh5),部署在hadoop2.0.0-cdh4.7.0版本上一直不成功,决定重新编译spark1.0.0,...
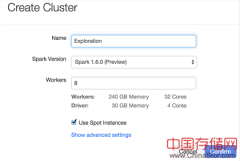
ApacheSpark在业内不断得到关注和应用,每一次的改变都牵动着从业者的心,这篇文章总结了ApacheSpark1.6预览版的一些新特性,并做了简短的介绍。...
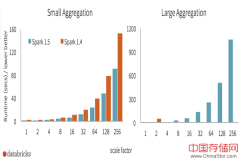
ApacheSpark1.5版本发布了,这篇文章概述了Spark1.5中的几个主要开发主题与一些令人期待的新功能特性。Spark1.5的大部分重大改动位于底层,更好地提升Spark的性能、可用性以及操作稳定性。...
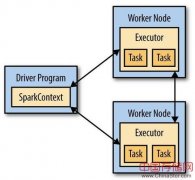
自2014年3月份跻身Apache顶级项目,Spark已得到业内广泛的支持。然而,对于一个高速发展中的开源项目来说,Spark的生产环境使用无疑还面临诸多挑战。8月6日晚的微信群讨论中,周小四为Spark的学习提出了一些指导。...

Spark1.4版本正式发布,在SparkCore、SparkStreaming、SparkSQL(DataFrame)、SparkMLMLlib等升级之外,新版本还加入了SparkR组件。下面一起看看SparkR和本次更新的介绍。...

过去一年,Spark从开源到火爆,展现了其成为通用大数据平台的潜质。本期封面报道“Spark新特性,新实战”内容涵盖SparkSQL、SparkMLlib、Tachyon、HiveonSpark多项技术,展示了基于Spark的架构迭代及性能调优。...

50个机构250个工程师贡献过代码,和去年六月相比,代码行数几乎扩大三倍,这是个令人艳羡的增长。那么,究竟是什么支撑了Spark如此的增长,对比Hadoop又有什么优势,这里一起揭开。...